OpenAI Scholar, Week 1
08 Jun 2018
. category:
DL
.
Comments
#openai
As a scholar, I will be writing a blog post every Friday this summer about my weekly progress and learnings. My last post described my search for a motivating project:
I will attempt to generate topical, structured, and specific new writing (“reviews”) about songs, based on a set of characteristics about the song and knowledge of past human music writing.
Like much about this summer, this is a goal post that may shift as I learn what’s possible. Here is how my first week went.
Part I. Where did all my data come from?
Hype Machine is a music blog aggregator, and as a HypeM paid supporter, I requested access to their developer API. With that, I retrieved about 10K unique songs from the site’s weekly popular charts, over the last 5 years.
The API is nice, and I was able to branch from the retrieved song list to the urls of blog posts about each song. The 10K songs produced ~80K review urls.
I didn’t want just any old post though (e.g., many blogs highlight multiple tracks in a single “roundup” post, whereas I would like posts that focus on a single track), so I did some data cleaning to filter by properties of the urls.
There was also attrition from retrieving the actual contents of the posts from the original sites (using the free Mercury Web Parser API).
Finally, I wanted reviews of songs that were also available on Spotify. This is so that I can retrieve interesting characteristics about the songs later in the summer (from Spotify’s Audio Features and Artist Genres APIs).
See the review count funnel/filter down to ~30K reviews, as well as word count distribution per review:

|

|
The mean word count in a review is 132, and there are almost 4M total words.
Part II. Generating terrible music reviews with n-grams
Once I had my music review corpus, I put it to work by training a very simple (and not deep) Unsmoothed Maximum Likelihood Character Language Model, or n-gram language model, for short. I wanted to understand how ‘hard’ language modeling1 (and therefore, my summer project) would be without deep learning, as well as establish a baseline model in week 1.
The model is mostly swiped from Yoav Goldberg’s post “The unreasonable effectiveness of Character-level Language Models (and why RNNs are still cool)”. For more about my experimentation with the model, you can check out this notebook.
Here I will instead provide some intuition with the following animation.
 Figure: what a character-level bi-gram model trained on the phrase “This is the remix.” might output.
Figure: what a character-level bi-gram model trained on the phrase “This is the remix.” might output.
The dictionary on the left represents what the bi-gram (n=2) language model (LM) has learned about how to generate characters from the phrase “This is the remix.” Each key is an observed bi-gram, and the value dict contains all characters that the LM has learned can follow each bi-gram, as well as the probability that the character would follow. As you can see, the next char options are very limited.
Note that we prepend ~~ to the phrase in order to teach the LM how to start a phrase.
On the right, we see variations of what the LM generates. The highlighted chars represent the current history, or the sequence of n(=2) characters for which the LM can guess the next char based on. The history is a form of memory for the LM - and its memory is very short!
Note that the green generation path is the happiest path, as it is the most sensible (and also a blatant copy of the training data!). But the blue generation path becomes possible once the LM’s memory only holds ‘s_’ (where ‘_’ is a space) - from its perspective, ‘i’ and ‘t’ as the next char seem equally reasonable. The red generation path is the saddest - the LM gets stuck repeating ‘is’ forever (this is a bit of an exaggeration for this LM - but for demonstration purposes, imagine that the probability of ‘i’ following ‘s_’ was way higher than that of ‘t’ following ‘s_’).
What I like about this demonstration is that it becomes easy to see 1) why memorization is often the easiest way to generate sensible output for such a simple model, and 2) how seemingly strange outputs like repeated ‘is’s or ‘the’s can occur.
You can also imagine what might change in the animation if we used 4-grams instead of bi-grams (from n=2 to n=4). It would be even easier to generate sensible but memorized output because there would be fewer 4-grams to choose from. In other words, the higher the order (n), the more consistent (sensible) the output - but also, the more capacity the model has to simply memorize the training data.
I make other observations about the n-gram LM in the notebook. You can also see more examples of terrible generated music reviews. But for now, let’s leave off with some of my personal, cherry-picked favorites:
- “thickas M801Qut tod stat fras n in” (n=1)
- “A truly gorgeous.” (n=6)
- “ups the risque with raw, provocative vocals as they take to the heavens, with lucid electronics mingle against skittering anthemic choruses are extremely memorable” (n=10, where the LM stitched existing phrases together into something almost new)
- “9 maging on **Com Tenfjord Resolvin Murphy people do” (n=4)
- “Serene vocals swell over my words about the track below” (n=8, which I think is my favorite order)
- “Meanwhile, the bass.” (n=8)
Part III. My summer curriculum
My syllabus for self-study during this program can be viewed on GitHub: openai/syllabus.md. This will be a living document, updated when necessary as the summer progresses.
Part IV. Why I chose PyTorch (over TensorFlow)
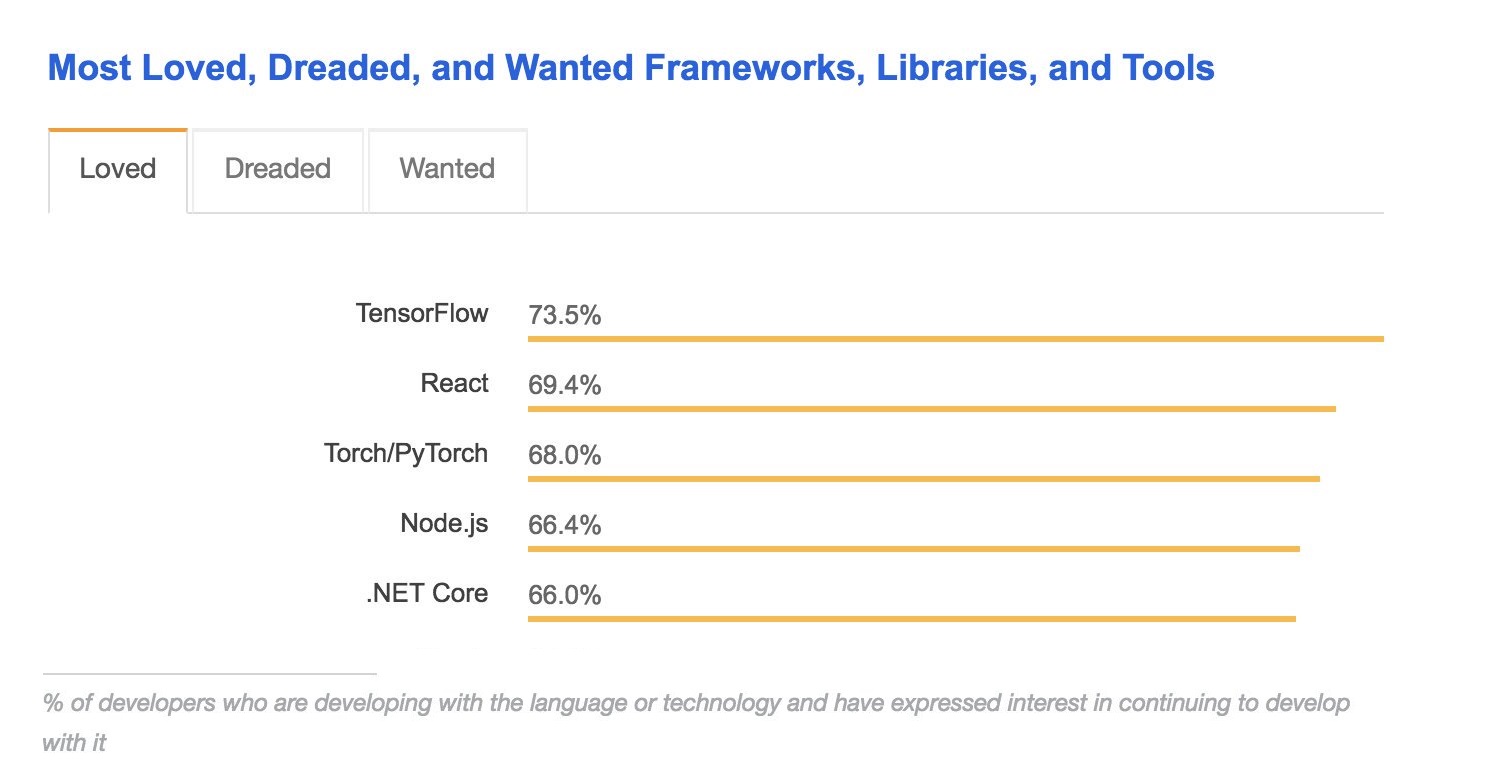 From StackOverflow’s Developer Survey Results 2018.
From StackOverflow’s Developer Survey Results 2018.
Deep learning frameworks provide useful building blocks for designing, training, and validating deep neural networks. They offer functionality like GPU-accelerated computations and automatic differentiation for computing the gradients necessary for deep learning.
Two of the most popular frameworks are TensorFlow (developed by Google Brain) and PyTorch (developed by Facebook AI Research).
What TensorFlow excels at:
- Greater adoption; larger community with lots of tutorials and documentation available online
- Hundreds of pre-trained models available
- Favored at many established AI research centers (including OpenAI)
- Tensorboard is apparently awesome for visualizations
- There is no equivalent in PyTorch
What PyTorch excels at:
-
Dynamic computation graph, allowing users to write regular Python code and use regular Python debugging while defining, changing, and executing nodes as you go
- Meanwhile, TensorFlow’s static computation graph has been described as feeling like “your model is behind a brick wall with several tiny holes to communicate over.”
- PyTorch’s dynamic computation graph is also more suitable for the variable-length sequential inputs common in recurrent neural networks (RNNs). RNNs are the cornerstone architecture for the language modeling work I’ll be doing all summer long.
- PyTorch LSTMs (an RNN variant) have also been benchmarked as faster than TensorFlow at default settings (you can get TF to be just as fast, if you know what you’re doing).
- More developer-friendly, as it contains many useful abstractions and employs familiar OOP constructs
- PyTorch community is newer but gaining momentum
For me, the deciding factor is PyTorch’s (alleged for now) better development and debugging experience. My mentor Natasha has advised me to be prepared to really poke and prod at my models when they refuse to train. My biggest concern with my choice is a lack of support for when things do go wrong, both from Natasha (who uses TF) and the greater deep learning community.
I’m also not sure how much of developer “interest in continuing to develop with” TensorFlow (or PyTorch, for that matter) is due to how amazing it actually is, versus having limited options for deep learning frameworks (especially compared to the ‘loved’ web frameworks on the list, in which there are dozens of options to choose from).
Helpful resources for making this comparison:
- “PyTorch vs TensorFlow — spotting the difference”
- “Introducing Pytorch for fast.ai”
- “Simple LSTM based language model in PyTorch vs Tensorflow”
- “PyTorch vs. TensorFlow: 1 month summary”
Bonus: This Is The Remix
Girl Talk is a mashup artist who was most active in the 2000s. His mashup “This Is the Remix” from his All Day (2010) album inspired the phrase that trained my example bi-gram language model in the animation from earlier on ![]()
Follow my progress this summer with this blog’s #openai tag, or on GitHub.
Footnotes
-
Language modeling: an approach to generating text by estimating the probability distribution over sequences of linguistic units (characters, words, sentences). ↩

Nadja does not particularly enjoy writing about herself.