OpenAI Scholar, Week 2
15 Jun 2018
. category:
DL
.
Comments
#openai
I spent a busy week training recurrent neural networks (RNNs) using PyTorch, with the ultimate goal of training a long short-term memory (LSTM) network, as promised by my syllabus.
Contents:
- The limitations of n-grams
- Getting familiar with RNNs (+ textgenrnn)
- PyTorch: first impressions (+ fastai library)
- This week’s struggles/learnings
- Program updates (+ other scholar blogs)
Part I. The limitations of n-grams
But why use RNNs when I generated such amazing text last week?
Just kidding. While the Unsmoothed Maximum Likelihood Character Language Model generated a few gems, a lot of it was either nonsensical or plagiarized from the training text.
N-gram models generally have issues like the following:
- The smaller the order
n, the higher the bias; the larger the order, the higher the variance [Jacob Eisenstein]. Practically, this means a smallnwill underfit, struggling to represent the true distribution of the language, while a largenwill overfit, being very dependent on whatever data happens to be in the training set.
The bias-variance tradeoff. Image adapted from "Understanding the Bias-Variance Tradeoff" by Seema Singh.
- A restricted or fixed context like
nmeans that any information outside of the context window is ignored [Jacob Eisenstein]. So structural things like closing a quotation, or linguistic things like subject-verb agreement can only be learned with a very largen. - But aside from overfitting, a larger
nmeans an exponentially increasing number of parameters to fit [Daniel Jurafsky & James Martin]. The curse of dimensionality - bad for learning. - Jurafsky & Martin also call out n-grams for their inability to “generalize from training to test set.” Compare this to RNNs and their representation learning, which can “project words into a continuous space in which words with similar contexts have similar representations.”
- Alex Graves, in his paper Generating Sequences with Recurrent Neural Networks (2014), compares ‘fuzzy’ RNNs to ‘template-based’ algorithms - which points squarely at the duplicating behavior of the n-gram model, particularly at higher orders.
Too small an n and you lose context; too large and you make training difficult and brittle. And even if some magical n sweet spot exists, it won’t generalize to a test set!
In order to generate more complex and compelling text, let’s turn our attention (foreshadowing) to neural networks!
Part II. Getting familiar with RNNs
Recurrent neural networks are a huge topic, in a summer of huge topics. This week, I tried to strike a balance between training the best RNN I can train (i.e., using other people’s code), versus training the best RNN I can fully understand in a week (i.e., putting networks together with only fundamental building blocks).
I trained a few of each type of network this week. The full, messy notebook is here. Note: I’ve only trained on a sample dataset (~2K reviews) so far.
| Computational Graph | Notes | Sample Text (seed='the ') |
|---|---|---|
NGram
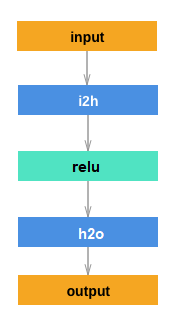
|
Just one more thing before RNNs! This is similar to last week's model, but as a feedforward neural network (meaning, data flows in one direction and there are no loops). Training time for 5 epochs: 1h 34m 27s (18m 53s/epoch) |
the t e oo o e toettoooteooee o te o eet eet et o ote oeeo teetoe t ete et eteoe eoe ooettet oe eoeo |
MyRNN
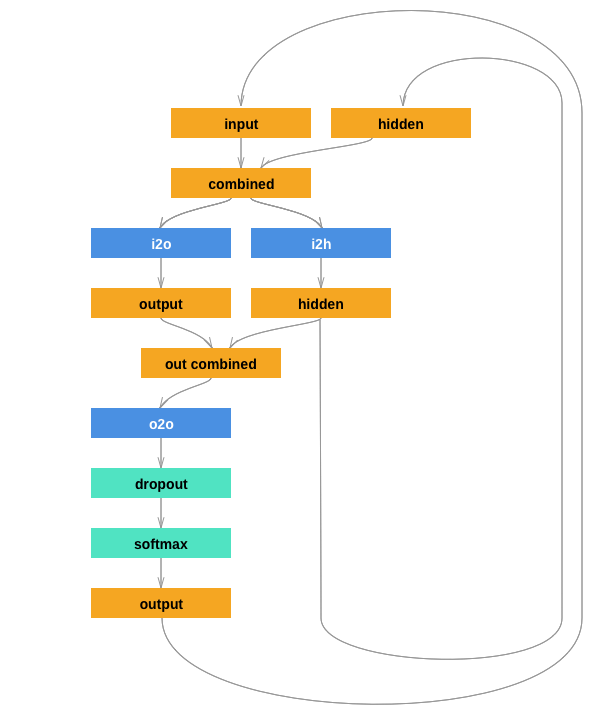
|
Adapted a recurrent architecture (notice the loops!), without using the PyTorch RNN layer. Training time for 5 epochs: 2h 1m 48s (24m 21s/epoch) |
the 2cwap% jaig aciph} araygay iblptoare josa7, pha]ptpjry iot, il) aydin t?e iruphy bol war |
PyTorchRNN
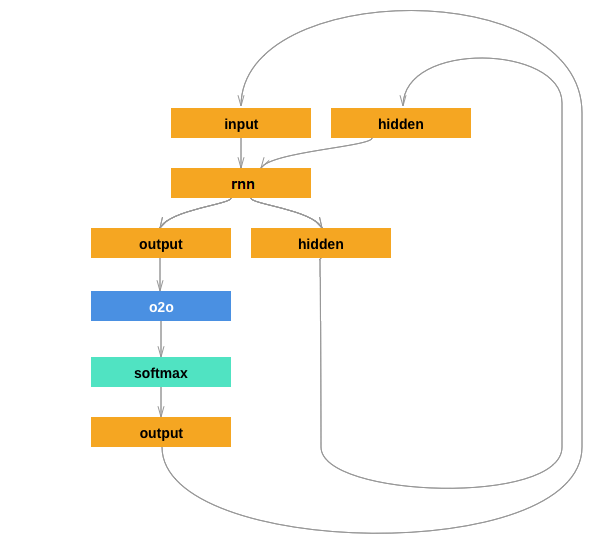
|
Using the PyTorch RNN layer. This helped me figure out how to implement batching, which helped speed up training a lot! Training time for 1000 epochs: (5.51s/epoch) |
the || ouzze bdyckeckuckick nd rd st checnezvouvee le"sod (sunoinondonst s g**gy'w dyeni da ts rdms dic |
|
FastRNN (same computational graph as PyTorchRNN) |
Using the same PyTorchRNN layer as above, but with the fastai library. fastai's fit() tracks loss, time, training loop, and its dataloader handles batching. Very convenient! It also trained PyTorchRNN faster and better (lower loss more quickly). Training time for 8 epochs: 11s (1.47s/epoch) |
the geren's beant, feell. out of yfuc wast and is soces** unsic // shear's memoterayd?** borustaria thistracome 'pre offacgino:*** **i| apol shopes ient shos alours songs dese --chate of diss, he gear the music /moding " ____ |
|
GRU (same computational graph as PyTorchRNN but with 'gru' for 'rnn') |
An RNN variant that's meant to be more computationally efficient than an LSTM. Training time for 9 epochs: 12s (1.42s/epoch) |
the and - sing all parts **her, ap solas edy opting anyth is collicofing and bar cono albud: it on thative have also, packer likes in face, leef well ever** |
|
LSTM (same computational graph as PyTorchRNN but with 'lstm' for 'rnn') |
The main event! An RNN with memory that allows it to control what it remembers and forgets over long ranges. Training time for 78 epochs: 2m 29s (1.92s/epoch) |
the music your" is to be're brand part, kennehom over top with" places, guite perfedday some sung due (halbina" saintaway if you theinvipled fries. |
Footnote on table visualizations.1
Going forward, there are so many things I could tweak - hyperparameters, architectures - but Natasha gave me good advice to focus this week on just getting to an LSTM that trains.
Is this an improvement on the text from last week? Not quite. I’m glad that next week will give me more time with LSTMs, now that I have a grasp of the fundamental building blocks.
For a great explainer on RNNs, LSTMs, and GRUs, check out Denny Britz’s series on “Recurrent Neural Networks”.
textgenrnn
For a fun break from my own garbled generations, I fed the same sample reviews into textgenrnn, a TensorFlow-based project that takes inspiration from both the original char-rnn project and DeepMoji, which I’m a fan of.
The project makes it really easy to try it out on Google Colaboratory, so I did! You can see the full, messy results here.
I trained both a character-level and word-level LSTM. Here are two cherry-picked samples at 0.5 temperature2.
| char-level LSTM | word-level LSTM |
|---|---|
| have something that something up with a made through the time of the listener with the producers that see more intern at San Mei and Jeremas are the country of funk of the same charm of the most pop sound of the songwriting of the mood. The song is a song about the way to recording his songs | the song is a powerful , stirring and drums and emotive but with rhythmic , and lighthearted chimes are a perfect backdrop for a more atmosphere . the track is the perfect blend of the track is a beautifully effervescent pop number with a cascade of psych - pop , the track ' s vocals the twosome ' s mournful energetic yet smooth , and the neon of the track pours over the course of the beat . it ' s about coming out now , but also always a small handful of 2017 and if you hear that of these tracks they have to expect to work with a brand new project called _ * * sketches . " * * |
To be fair to the character-level sample, I only trained it for 5 epochs (compared to 10 epochs for word-level) because it takes longer.
They’re both pretty pleasing (word-rnn more so)! This quick jump forward renews my belief that LSTMs are capable of generating expressive music reviews.
For more on the textgenrnn project, check out the blog post: “How to Quickly Train a Text-Generating Neural Network for Free”
Part III. PyTorch: first impressions
Last week, I explained my decision to give PyTorch a spin this summer. One week in, here are my first impressions:
- The official tutorials are quite good - and so are some unofficial ones. They really helped me get off the ground with PyTorch this week.
- PyTorch really does feel like Python! I like how closely tied to
numpyit is. I also haven’t been tripped up by the philosophy of the library itself yet. - Via Google searches, discuss.pytorch.org has been very useful for debugging small issues so far. I’m glad that the community is so active.
- I do wish that the official docs weren’t long pages with multiple topics on each page. Each page contains a module, and modules can have many functions. It makes Google searches for a particular function hard, and I frequently had multiple tabs with the same page open, just scrolled to different parts. I guess they expect us to use their internal doc search?
fastai library
Did you notice that the last 3 RNNs in the table above (FastRNN; GRU; LSTM) trained epochs in ~1s, compared to the ~5s it took my train loop (with batching) for PyTorchRNN? That’s an 80% improvement!
Alongside convenience functions, I have to thank the fastai PyTorch library for the impressive speed up!
I could continue grinding out incremental progress on my naive RNN implementations from this week - but for better convenience and reliability, I plan to use the fastai library from now on. It’s been formally benchmarked as fast (for computer vision tasks).
Here are some other perks:
- Lots of example code (after all, there’s a whole course built around it!)
- Convenient functionality like dataloaders with built-in batching, model saving, and a
fitfunction - Jeremy claims it is easy to customize the library when needed… TBD on that
On the downside, it is hard to know if or how much the library is optimizing things under the hood without digging into the source code.
For example, I only happened to notice that the language model dataloader has implemented randomized-length backpropagation through time (BPTT) - which, great for my model performance, but hard for learning about exactly what makes my model tick.
Part IV. This week’s struggles/learnings
Here are some of the difficulties and a-ha moments I had during the week.
Tensor dimensions
I had trouble keeping track of the dimensions going in and coming out of my networks, and I don’t have intuitive sense of when to reshape (view) a tensor before further use (yet).
So often, I reshape tensors due to an explicit dim mismatch error - and when I finally get things running again, I don’t know why the reshape was necessary (if it runs, is it always valid input?).
I don’t have a solution to this yet. I might try making expected dimensions more explicit in my code. For intuition-building, Natasha suggested that I try using the Python Debugger (import pdb; pdb.set_trace()) to check the shape of tensors.
Defining loss
There appears to be two equivalent ways of defining multi-class loss in PyTorch.
- Make
nn.LogSoftmaxthe final layer called in theforwardpass. Then have an externalcriterionofnn.NLLLoss. [example] - Skip defining a final activation layer in the
forwardpass. Then have an externalcriterionofnn.CrossEntropyLoss. [example]
This was confusing to me at first. The nn.CrossEntropyLoss docs do mention that “This criterion combines nn.LogSoftmax() and nn.NLLLoss() in one single class.”
tanh vs ReLu?
I had a question early in the week about why I was seeing RNNs with tanh activation functions, when I had learned (from fast.ai and CS231n) that ReLu is the go-to activation function for hidden-to-hidden layers.
It turns out that PyTorch does not support ReLu activations in its LSTM and GRU implementations! [issue#1932] ReLu is an option for vanilla RNNs, but tanh is still the default. This was surprising to me - it’s probably a side effect of how quickly best practices change in the field.
Program updates
Syllabus edits
Here’s a changelog for what I updated in my syllabus this week (see full commit if super interested):
- Updated my resources list for this week (2) based on what I actually ended up using
- Combined weeks 4-5 (seq2seq + seq2seq with VAE) into one week (4) on seq2seq models
- Move week 6 up to week 5 and rename to “Classification with Attention” (formerly, “Model interpretability, part 1”)
- Split week 7 into weeks 6-7 on “Model interpretability” - one to survey explicit methods for interpretation, the other to study bias in my own models
Scholar blogs
I’d like to share and promote the blogs of the other amazing OpenAI Scholars! They can be found below:
- Holly Grimm https://hollygrimm.com/
- Christine McLeavey Payne http://christinemcleavey.com/
- Munashe Shumba http://everyd-ai.com/
- Dolapo Martins https://codedolapo.wordpress.com/
- Ifu Aniemeka https://www.lifeasalgorithm.com/
- Hannah Davis http://www.hannahishere.com/
- Sophia Arakelyan https://medium.com/@sophiaarakelyan
Follow my progress this summer with this blog’s #openai tag, or on GitHub.
Footnotes
-
Wow, look at those computational graphs! How did I draw them?! With MS Paint + a good template from a tutorial. If I have time, I’d like to look into viz libraries for printing the PyTorch autograd graph directly (since there’s no official Tensorboard equivalent). ↩
-
Temperature is meant to represent the ‘creativity’ of the text. It controls how suboptimal sampling for the next char or word is allowed to be. The lower the temperature, the more confident the predictions - but also the more conservative. 0.5 is middle of the road. ↩

Nadja does not particularly enjoy writing about herself.