Not Enough Attention
06 Jul 2018
. category:
DL
.
Comments
#openai
Attention week: what an ironic week to get distracted.
My stated goal for week 5 was to adapt an LSTM-LM1 to do classification with attention. Because I still don’t trust the genre labels I pulled from the web (as mentioned last week), I decided I would try to enter a Kaggle competition that would provide a cleaned, labeled data set to work with.
I chose to work on the Movie Review Sentiment Analysis competition (kernels only), one of the only two active NLP competitions at the moment. It’s a “Playground Code Competition” and the prize is “knowledge” rather than, say, $70,000.
This week, I spent much more time on figuring out transfer learning with LSTM-LMs (plus applying last week’s seq2seq VAE learnings) than I did on applying attention. Meanwhile, attention received a high-level treatment.
To skip ahead to my attention explainer, click here.
Kaggle + ULMFiT
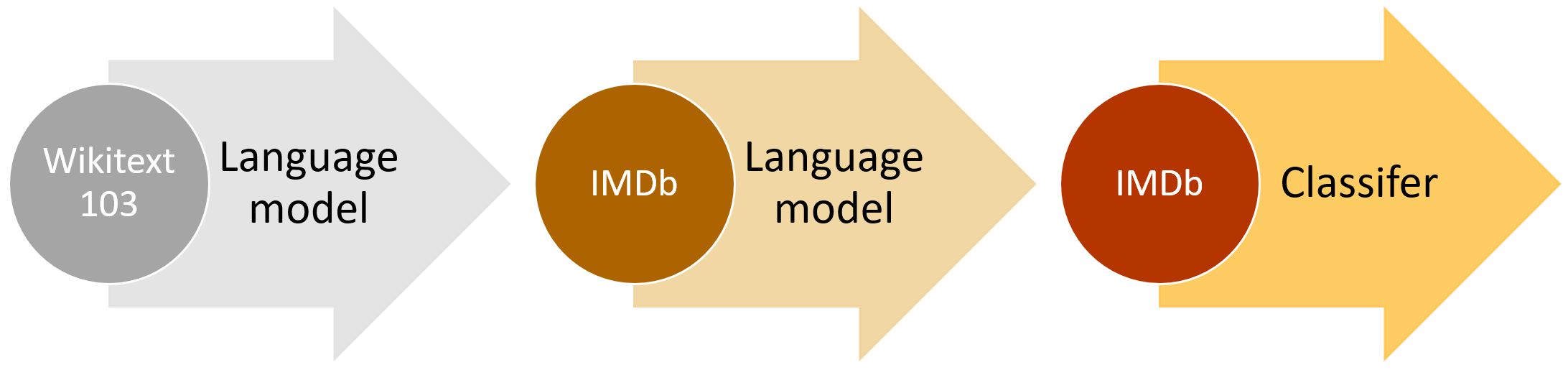 The high level ULMFiT approach. Image courtesy of “Introducing state of the art text classification with universal language models” by Jeremy Howard and Sebastian Ruder.
The high level ULMFiT approach. Image courtesy of “Introducing state of the art text classification with universal language models” by Jeremy Howard and Sebastian Ruder.
I did eventually enter the competition, but without an attention mechanism (I talk more about why later). This is the first Kaggle competition I’ve entered without a lot of hand holding. I wrote about the pre-training process I used to enter the competition in my data set description:
Check out https://www.kaggle.com/iconix/ulmfit-rt/home for more details about my entry!
My entry is currently in the top 50%, which is ok-ish (top 5 public kernels though!).
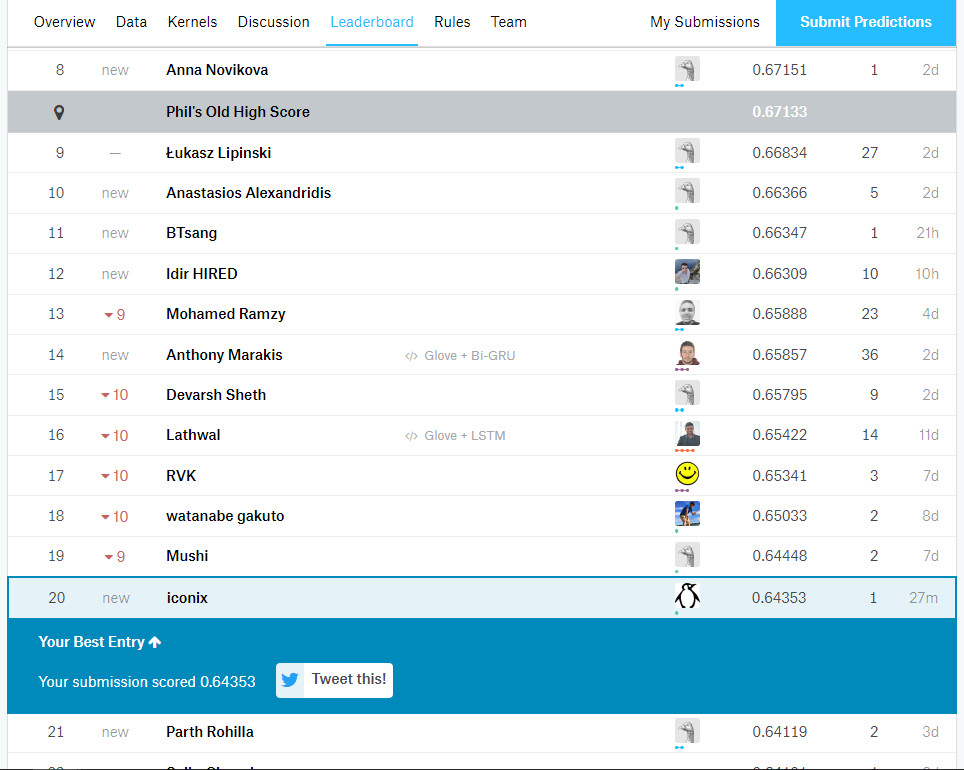 If you’re wondering why “Phil’s Old High Score” is distinctly highlighted (like I was): Phil Culliton of Kaggle explained that it’s meant to be a benchmark from a previous run of this competition. #themoreyouknow
If you’re wondering why “Phil’s Old High Score” is distinctly highlighted (like I was): Phil Culliton of Kaggle explained that it’s meant to be a benchmark from a previous run of this competition. #themoreyouknow
At the beginning of this week, I didn’t know what Kaggle meant by a “kernels only” competition. I ended up understanding and liking how kernels encouraged me to clean up, document, and share my work. I appreciated being able to peek at other public kernels to see other approaches and simple tricks (like an efficient way to create the submission .csv). It’s a neat, reproducible system, and while the web-based interface was buggy at times, it’s ultimately well-designed and flexible.
I’d like to re-enter the competition with the attention mechanism I originally intended to add. But first, what is attention anyway?
Understanding attention
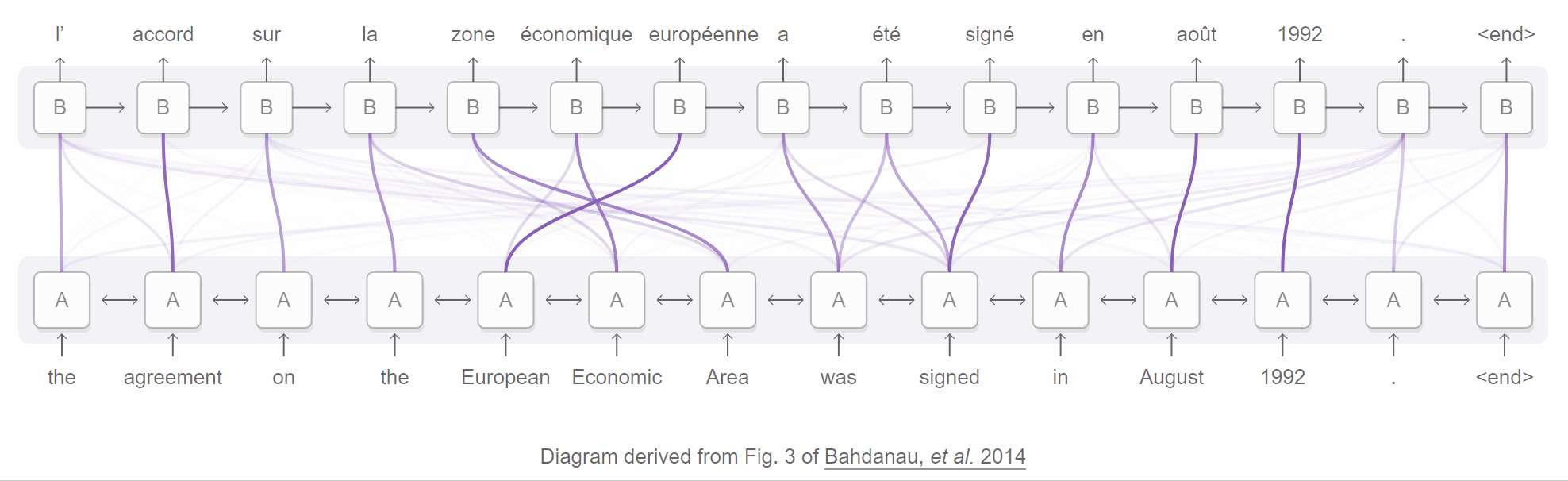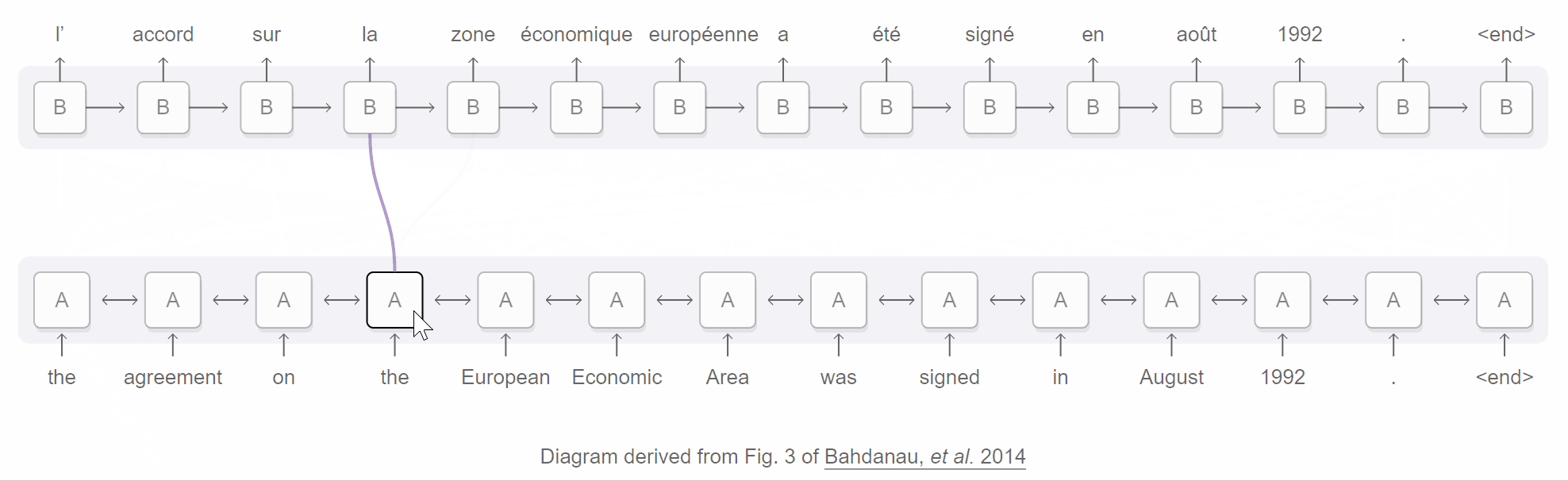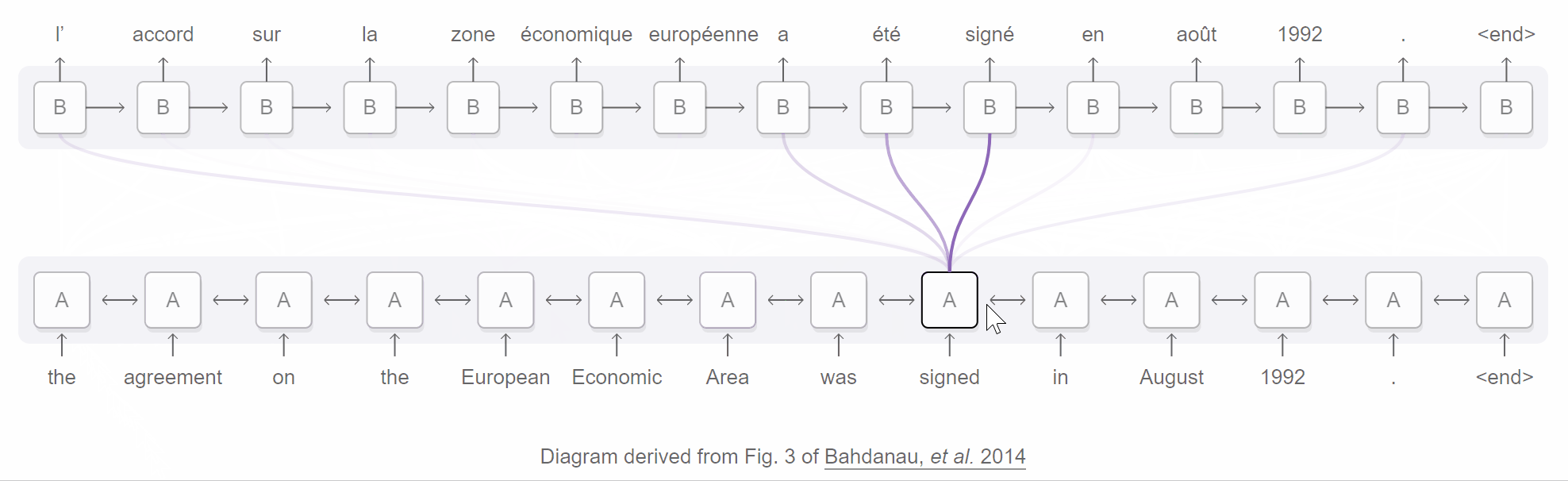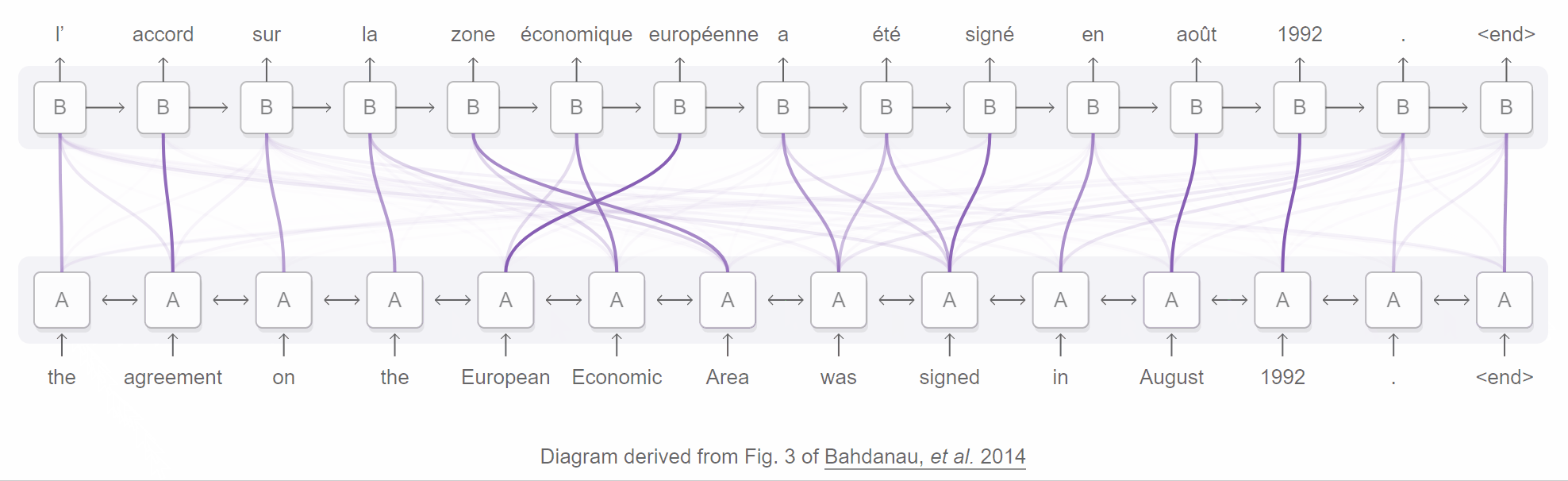 An attentional encoder-decoder network for neural machine translation. From Distill’s “Attention and Augmented Recurrent Neural Networks”.
An attentional encoder-decoder network for neural machine translation. From Distill’s “Attention and Augmented Recurrent Neural Networks”.
Attention is usually discussed in the context of regular (i.e., not auto) encoder-decoder networks2.
For regular encoder-decoder networks (doing tasks like neural machine translation), the thought vector is a clear bottleneck. While the thought vector encourages autoencoders to learn useful features of the data (rather than acting as the identity function), it is limiting for regular encoder-decoders.
It turns out this limit is unnecessary. Attention extends the encoder-decoder network by enabling the network to perform a sort of soft search for the most relevant information in the source sequence while predicting the target word. Rather than a single thought vector, each target word gets a distinct context vector, and attention allows the decoder to selectively retrieve information spread across these vectors.
Here’s how the attentive network described in the seminal Bahdanau et al. paper works:
- A bidirectional RNN encoder annotates each word in the sequence with info about the words surrounding it (both preceding and following, since it’s bidirectional). The annotation is simply a concatenation of the forward and backward hidden states of the word.
- For each target word to predict, the RNN decoder is provided a distinct context vector (contrast this with the single thought vector). Each context vector is a weighted sum or weighted average of the annotations provided by the encoder.
- The weights assigned to the annotations are determined by the attention mechanism, which is a feedforward (i.e., no loops) network in front of the decoder. Intuitively, the attention mechanism uses these weights to decide which annotations each word “pays attention” to.
Because one can inspect these weight assignments to see what the decoder pays attention to at any given time step, attention can boost the interpretability of a network. You can even visualize what a network attended to at each step, as the Bahdanau et al. paper and GIF above demonstrate.
Self-attention
I will also touch briefly on the self-attention (or intra-attention) mechanism, first introduced by Paulus et al. in A Deep Reinforced Model for Abstractive Summarization (2017) and then popularized by the Transformer architecture introduced in the Attention Is All You Need (2017) paper by Vaswani et al.
While the original attention mechanism learns dependencies between a source and target sequence, self-attention learns dependencies within a single sequence. It computes the relevance and relationships of the other words in the sequence to the target word. This idea is so powerful that the Transformer architecture was able to completely eliminate the RNN encoder and decoder, replacing them with self-attention for learning how the words in a sequence relate!
Self-attention has a few other advantages:
- Long-distance dependencies are more manageable because relationships between words are modeled as positionally invariant.
- Unlike RNNs, self-attention does not rely on sequential processing, so computations can happen in parallel (taking advantage of what GPUs do best).
- Using self-attention for seq2seq is more computationally efficient (fewer number of steps) than both RNN-based and convolution-based seq2seq networks.
I’ll leave off with my favorite visualization from Google’s blog post on the “Transformer: A Novel Neural Network Architecture for Language Understanding”:
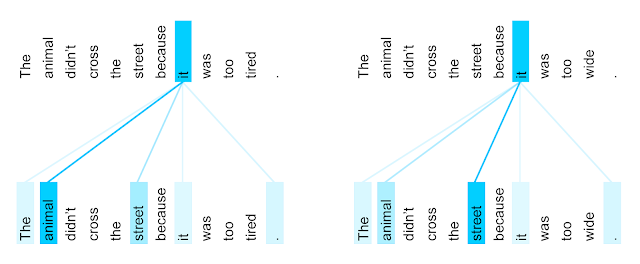 How the Transformer works: it “starts by generating initial representations, or embeddings, for each word. … Then, using self-attention, it aggregates information from all of the other words, generating a new representation per word informed by the entire context. … This step is then repeated multiple times in parallel for all words, successively generating new representations.”
How the Transformer works: it “starts by generating initial representations, or embeddings, for each word. … Then, using self-attention, it aggregates information from all of the other words, generating a new representation per word informed by the entire context. … This step is then repeated multiple times in parallel for all words, successively generating new representations.”
The Transformer’s ability to understand that “it” is the “animal” in the context of “it” being “tired”, while “it” is the “street” in the context of “it” being “wide” (also known as coreference resolution) – that’s totally bonkers to me.
Definitely do check out the full blog post and paper!
Diversions and a Breakthrough
On a more personal note, I’d feel amiss not to talk about the struggle I’ve had with sticking to my own schedule this summer, and the mental shift I’m working to embrace.
Here’s a non-exhaustive list of things that ended up distracting me from my stated topic of the attention mechanism this week:
- Ramping up on the competition’s Rotten Tomatoes movie review data set (the format was not what I was expecting).
- Ramping up on using language model transfer learning and fine-tuning for text classification (à la ULMFiT).
- Getting lackluster results with said transfer learning using the competition data, then figuring out that fine-tuning with IMDB first worked much better.
- Trying to make a dent in my model training infrastructure debt.
- Adding sampling to my seq2seq VAE code fork from last week3.
And I could have made a similar list every week of the program so far.
I’ve been trying to fight through a pattern that’s emerged week after week for me so far as a scholar – and I think I’d do better to just embrace the pattern. When designing my syllabus, I scheduled one full week each to both learn and implement some heavy topics: RNNs, conditioned LSTMs, seq2seq VAEs, and now the attention mechanism.
But with each topic so far, it’s taken me about that one week just to understand the concepts at a high-level and start tinkering with code. I’ve only internalized each topic well enough to reasonably apply it by the following week.
So instead of feeling like I’m failing in some way every week, I am taking the hint that I just need a little more time with these topics, and that is totally fine. My syllabus has provided me with a clear, instructive path through the first 8 weeks of the program, and even if slightly delayed – I’m making a lot of progress, and I’m getting stuff done. This is what matters.
Next week, I expect to implement attention in an LSTM-LM model, as part of my first week on model interpretability (a topic I am particularly excited about).
Follow my progress this summer with this blog’s #openai tag, or on GitHub.
Footnotes
-
I started using the acronym
LSTM-LMlast week to mean LSTM-based Language Models. And while we’re here, a reminder thatLSTMstands for Long Short-Term Memory (good explainer). Later,seq2seq VAE== Sequence-to-Sequence Variational Autoencoder;RNN== Recurrent Neural Network;NLP== Natural Language Processing. ↩ -
By the way (because this was an idea on my syllabus draft for a while), an attentive seq2seq VAE would be ineffective. Why? The network is going to be as lazy as you allow it to be, and it just won’t bother learning to use a thought vector, variational or otherwise, when it can simply search with attention as needed. ↩
-
Quick sidebar follow-up from last week: I mentioned that the seq2seq VAE code that I forked hadn’t implemented sampling, so I shared the homotopies it could generate instead. My mentor Natasha then pointed out that sampling is actually very simple to implement. She was right (per usual) - so I added
generate.pyto my fork this week! ↩

Nadja does not particularly enjoy writing about herself.