Interpreting Latent Space and Bias
21 Jul 2018
. category:
DL
.
Comments
#openai
For week 7, and my second week on model interpretability (see first week post), I focused in on one particularly cool VAE-based visualization example from Ha & Schmidhuber’s World Models work. I also did some broader thinking around selection bias in my song review training data.
Playing in VAE latent space
I spent some quality time this week with the wonderfully engaging World Models project from David Ha and Jürgen Schmidhuber. It is really impressive to see such an interactive post accompany a paper like this!
I particularly enjoyed the demo that allows users to play with the latent vector z of a variational autoencoder (VAE) and see how it affects the reconstruction:
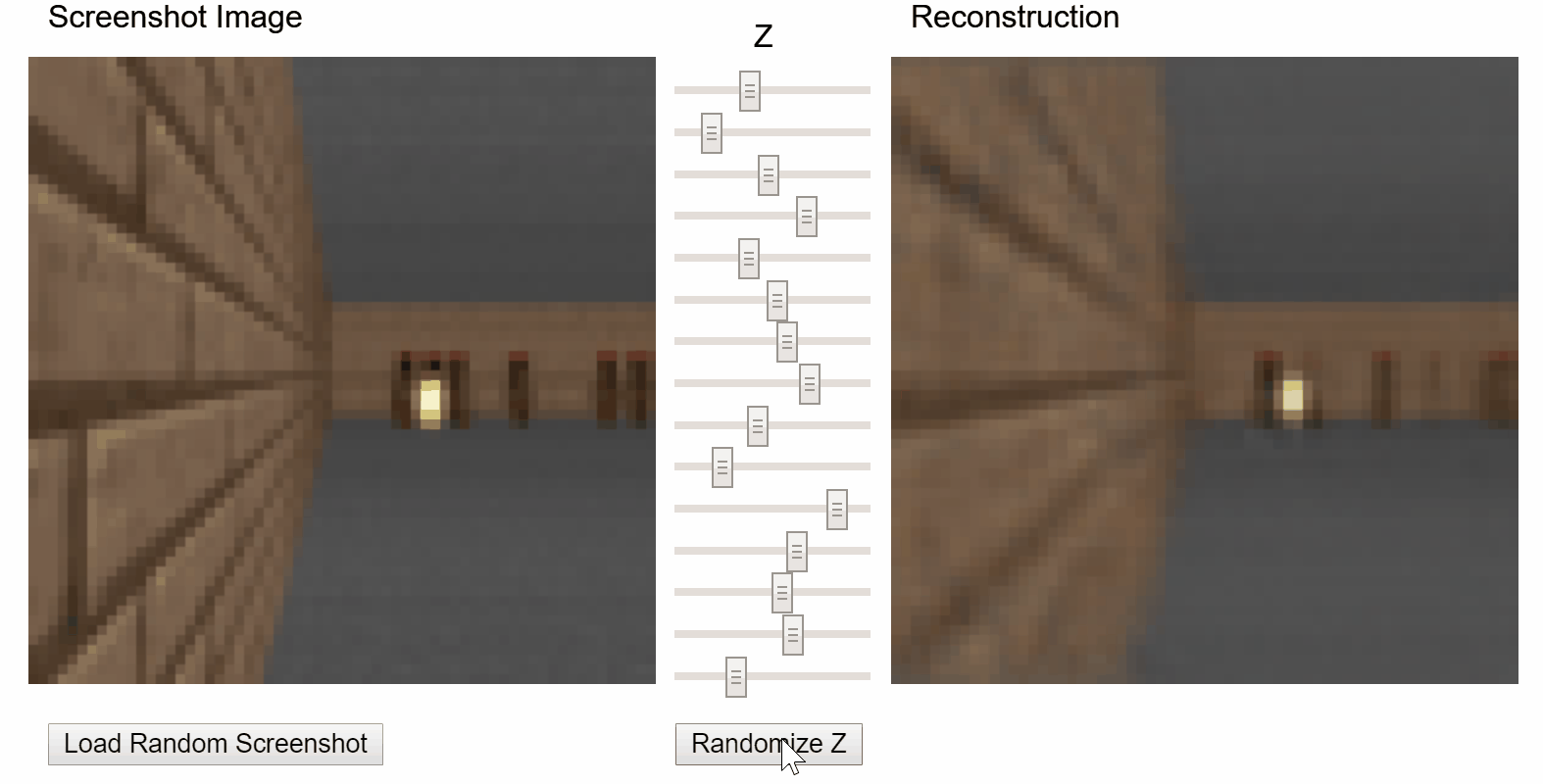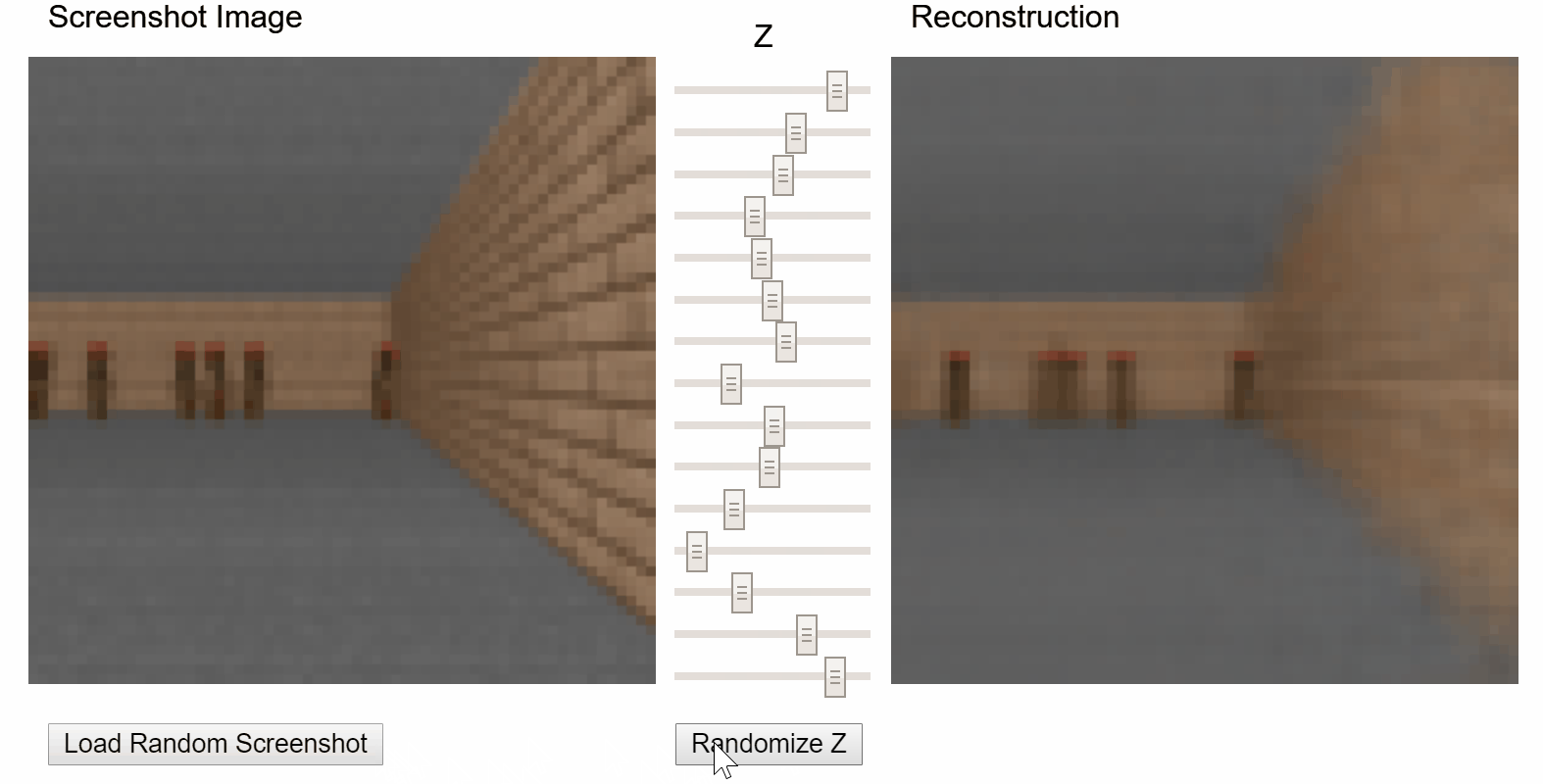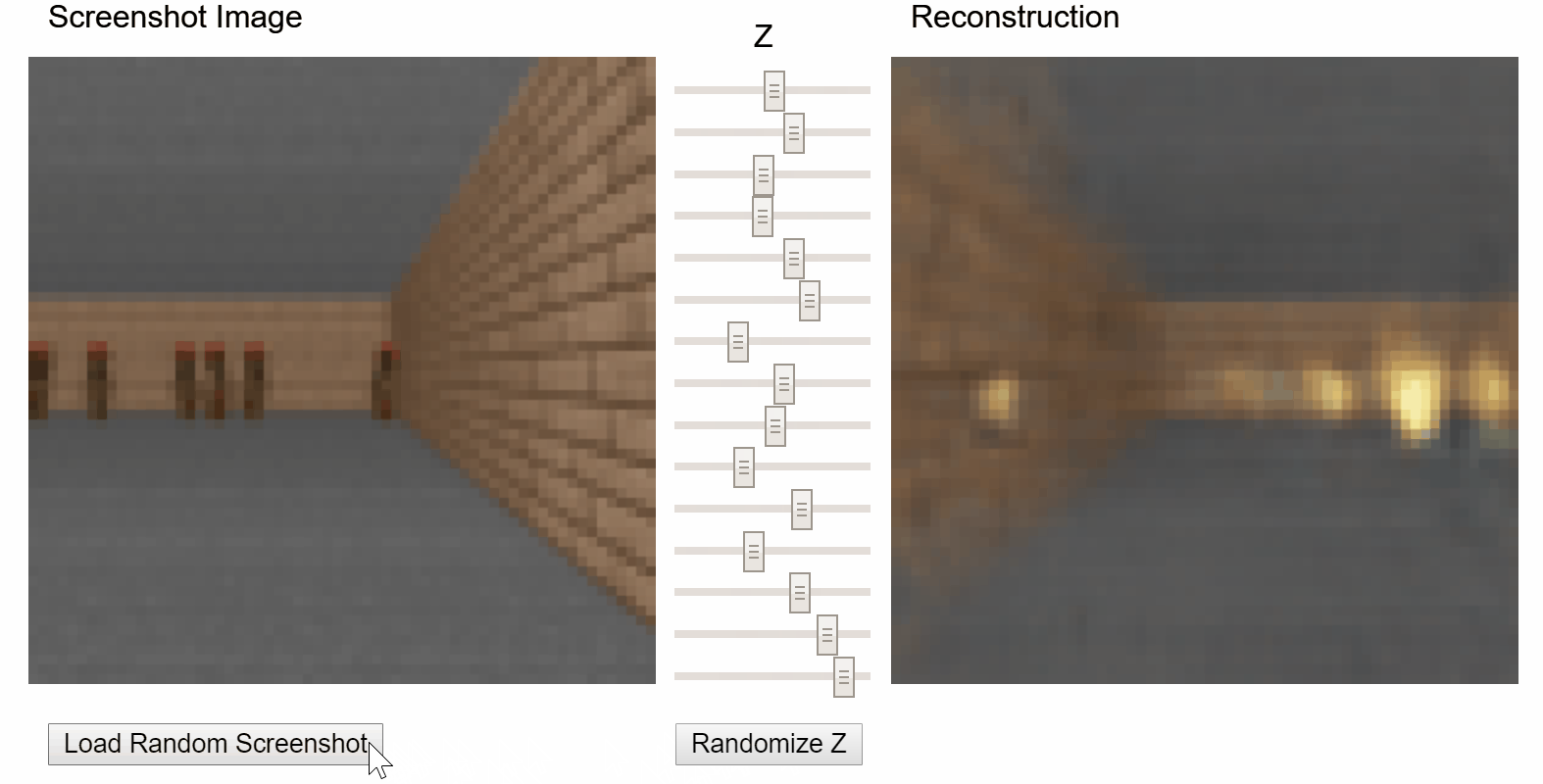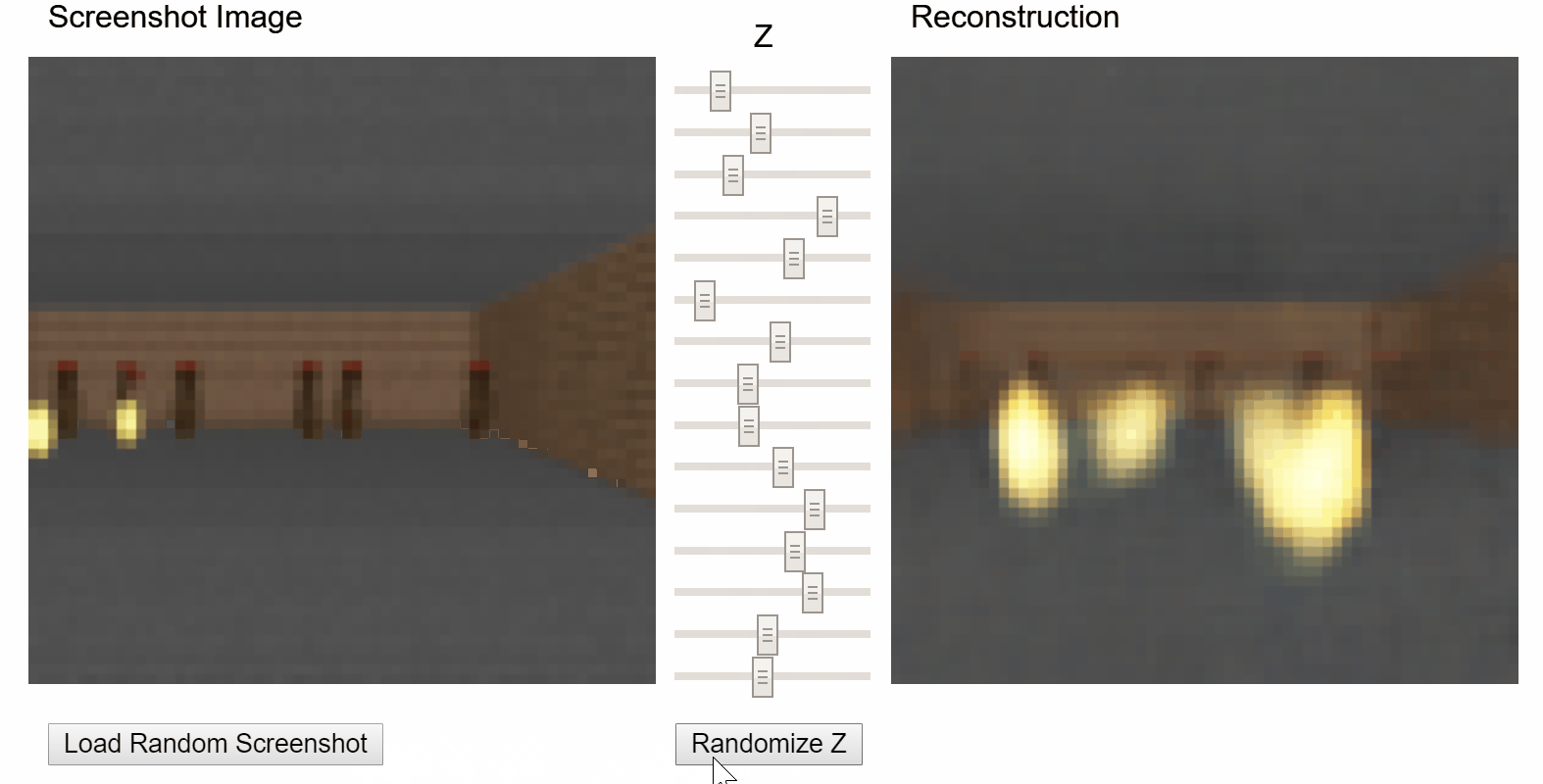 VizDoom VAE demo from original World Models project.
VizDoom VAE demo from original World Models project.
So I created my own scaled-down version of this demo! It features my text-based seq2seq VAE from earlier in the program that encodes sentences from my song review dataset, rather than frames from the video game Doom.
The VAE I trained in week 4 on sentences in song reviews. You can load sentences that the model reconstructed well using a particular latent vector z and experiment with adjusting the values of z to see how it affects the reconstruction. Inspired by Ha & Schmidhuber’s World Models demo1.
As a quick recap of week 4, the latent vector of a VAE attempts to encode or compress all of the factors of variation in the data that may be relevant for reproducing it. In the World Models project, it learns to encode aspects of the visual environment of Doom, like the player’s location and whether an alien is firing at the player. In my demo, it learns to encode aspects of text.
The z vector is actually a 128-dimensional vector. Because 128 knobs would be rather unwieldy, I used principal component analysis (PCA) to reduce dimensionality down to 5. Fortunately, PCA allows us to reverse its effect and reconstruct the z vector, making it feasible to compute all possible samples at each available step (3 available steps in this demo) of each dimension:
[\mathit{n_samples} = \mathit{n_steps}^\mathit{n_dimensions} * \mathit{n_sentences} = (3^5)*5 = 243 * 5 = 1,215 \mathit{samples}]
While these dimensions are not easily interpretable to me (i.e., it’s difficult to cleanly describe what dim1 might represent), it’s interesting to explore the possible space of sentences available. Many points in the space still produce coherent sentences and phrases, which is encouraging to see.
Selection bias
Since first crafting my direction and syllabus for the summer, centered around a data set of my own creation, I knew there were potential issues around where and how I get the data I wanted.
Put simply, I collected the data I collected out of convenience.

During college, I religiously used a little-known site called Hype Machine (HypeM) for discovering new music to add to my rotation. At the time, I was broke and used it for free, but now that I work, I am a paid subscriber. This subscription gives me access to their developer API, which gave me a great jumping off point for extracting music blog writing. Hype Machine is a brand that I personally know and trust - but this is a clearly biased perspective.
In relying on HypeM, I am making a value judgment that the HypeM blog list represents the only valuable type of music writing on the internet (and thereby excluding, for example, social music writing on platforms like Tumblr or Twitter); conversely, I’m largely assuming that all writing from this blog list is valuable.
HypeM is a single source that aggregates many blog sources. It was recognized (by folks like The Chainsmokers and VICE) as an internet ‘tastemaker’ in its heyday.
But then, what is taste? When the likes of The Chainsmokers and VICE sing your praises, whose tastes are left out? Take for instance SoundCloud rap, which is having a big mainstream moment right now. What happens if we (roughly) compare the performance of The Chainsmokers on HypeM to that of a Lil Uzi Vert, who has successfully transitioned from SoundCloud to the top of the charts?

|

|
Lil Uzi Vert:
- 1 #1 hit, 2 Top 10 hits, 23 total songs on Billboard Hot 100
- 42 tracks (3,129 times loved by community)
The Chainsmokers:
- 1 #1 hit, 5 Top 10 hits, 12 total songs on Billboard Hot 100
- 97 tracks on HypeM (188,696 times loved by community)
Billboard numbers are used here as an indictor of popularity, and The Chainsmokers and Lil Uzi Vert are fairly comparable. Yet The Chainsmokers have 2.3x more tracks listed on HypeM (including remixes by other artists) than Lil Uzi Vert. Granted, many factors can influence HypeM chart performance – but the EDM-pop Chainsmokers do seem a bit over-represented on HypeM.
Let’s throw in another rap group: Migos. Better Billboard numbers, but they still underperform The Chainsmokers on HypeM:
Migos:
- 1 #1 hit, 4 Top 10 hits, 32 total songs on Billboard Hot 100
- 82 tracks on HypeM (17,322 times loved by community)
In general, pop-leaning tracks dominate the HypeM popular charts. According to Genius.com labeling, here’s a single-genre breakdown of the last 5 years on Hype Machine:
| pop | 64% |
|---|---|
| rap | 15% |
| rock | 14.5% |
| r-b | 6.3% |
| country | 0.2% |
I’ve mentioned before not entirely trusting these labels - but assuming they are at least in the ballpark of accurate, the skew is clear. (UPDATE: I got much more trustworthy and interesting genre labels from the Spotify API and followed up with more genre explorations here!)
I could also detect anecdotal evidence of bias in the kinds of samples my models have been most willing to generate:
- bias towards certain locations, e.g., “Berlin-based producer” and “LA-based producer” (this also echoes the Germany/California split from week 4’s energy-conditioned LM word clouds)
- bias towards male-gendered pronouns, e.g., “his soulfully introspective” or “his debut/take/new track”
This is a high-level analysis, but I think it still emphasizes an important point: there are many opportunities for discrimination in deploying machine learning systems, and it is important to be self-critical as a machine learning practitioner.
Follow my progress this summer with this blog’s #openai tag, or on GitHub.
Footnotes
-
The original demo uses tensorflow.js, a JavaScript library for deploying ML models in the browser. Since I didn’t want to learn a new library right now, I instead pre-computed all samples offline with my PyTorch model. Check out my work notebook for a sketch of how the precomputing was done. ↩

Nadja does not particularly enjoy writing about herself.