deephypebot: an overview
31 Aug 2018
. category:
DL
.
Comments
#openai
Motivation
@deephypebot is a music commentary generator. It is essentially a language model, trained on past human music writing from the web and conditioned on attributes of the referenced music. There is an additional training step that attempts to encourage a certain type of descriptive, almost flowery writing commonly found in this genre.
Our goal is to teach this language model to generate consistently good and entertaining new writing about songs.
Project Achievements
- Model inference through pre-trained LC-GAN + CVAE deep learning architecture (details below)
- Open-sourced, documented pipeline code (GitHub repo)
- Open-sourced model training code (seq2seq CVAE; LC-GAN)
- A technical white paper (pdf)
Architecture

Training data
My training data consists of ~20,000 blog posts with writing about individual songs. The count started at about 80K post links from 5 years of popular songs on the music blog aggregator Hype Machine - then I filtered for English, non-aggregated (i.e., excluding “round up”-style posts about multiple songs) posts about songs that can be found on Spotify. There was some additional attrition due to many post links no longer existing. I did some additional manual cleanup of symbols, markdown, and writing that I deemed non-commentary.
From there, I split the commentary into ~104,500 sentences, which are a good length for a variational autoencoder (VAE) model to encode.
Neural network
A language model (LM) is an approach to generating text by estimating the probability distribution over sequences of linguistic units (characters, words, sentences). This project centers around a sequence-to-sequence conditional variational autoencoder (seq2seq CVAE) model that generates text conditioned on a thought vector z + attributes of the referenced music a (simply concatenated together as <z,a>). The conditioned embedding fed into the CVAE is provided by an additional latent constraints generative adversarial network (LC-GAN) model that helps control aspects of the generated text.
The CVAE consists of an LSTM-based encoder and decoder, and once trained, the decoder can be used independently as a language model conditioned on latent space <z,a> (more on seq2seq VAEs here). The musical attributes info conditions only the VAE decoder.
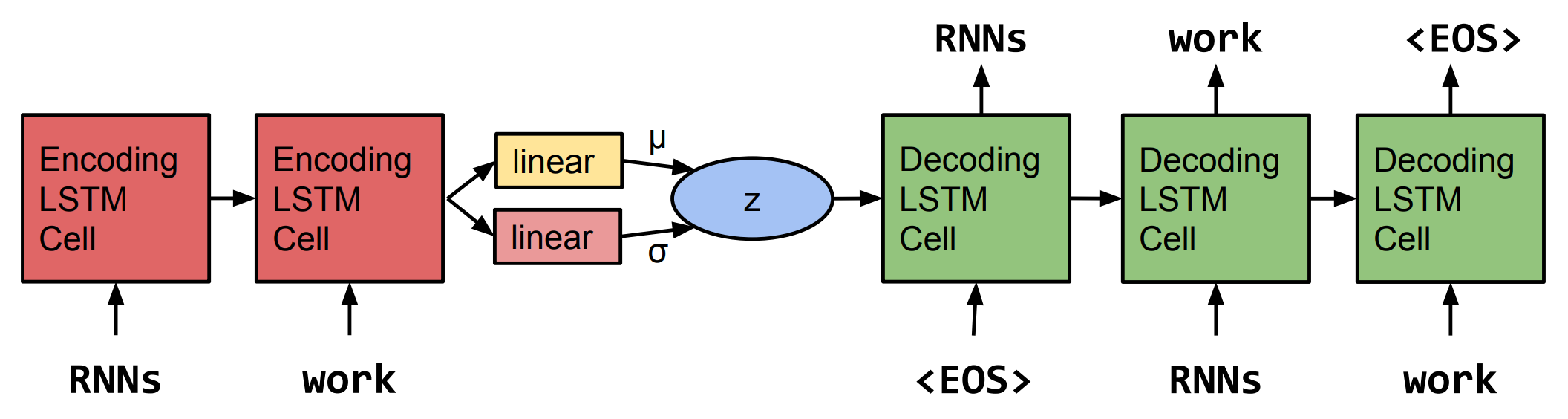 An unconditioned seq2seq text VAE. Replace
An unconditioned seq2seq text VAE. Replace z with <z,a> for a CVAE. Figure taken from Bowman et al., 2016. Generating Sentences from a Continuous Space.
The LC-GAN is used to determine which conditioned embeddings <z,a> fed into the decoder of this LM tend to generate samples with particular attributes (more on the LC-GAN here). This project uses LDA topic modeling as an automatic reward function that works with the LC-GAN to encourage samples of a descriptive, almost flowery style (more on LDA topic modeling here). The LDA topic distribution for the sentence associated with the <z,a> input provides the label v. The generator is trained to generate a z such that, when combined with a, <z,a> gives the ideal topic distribution v, as measured by the discriminator. Once trained, the generator can be used independently to provide these conditioned embeddings to the CVAE for inference.
 LC-GAN architecture.
LC-GAN architecture.
The seq2seq CVAE code used for this project is available here: https://github.com/iconix/pytorch-text-vae.
The LC-GAN code used for this project is available here: https://github.com/iconix/openai/blob/master/nbs/lcgan.ipynb.
Making inference requests to the network
Now that the neural network is accounted for, let’s discuss the engineering pipeline required to support inference live on Twitter.
While the model was developed in Python (PyTorch, conda environment manager), the pipeline is written using Node.js in order to run server-side JavaScript. This is due to how many convenient libraries already exist on npm for communicating with external services. The pipeline has two main components: a worker process and a multi-endpoint Express.js web service.
The web service essentially wraps existing APIs for Google Sheets, Spotify, and Twitter, providing a more convenient set of APIs to the worker. The worker process monitors Twitter at an interval (currently every 60s) for new tweets to appear on @deephypebot’s home timeline. New tweets are defined as any tweets that have occurred since the last tweet processed by this workflow (max as enforced by the Twitter API: 200 tweets). New tweets are parsed for song and artist information, and if this is found, the information is passed on to Spotify. If Spotify accepts and responds with genre information, this is then passed to the neural network (which is deployed behind a Flask endpoint) for conditioned language modeling.
From samples to tweets
Once multiple samples of commentary for a new proposed tweet are generated, they are added to a spreadsheet where the human curator (me) can select which samples are released to @deephypebot for tweeting.
Text generation is a notoriously messy affair where “you will not get quality generated text 100% of the time, even with a heavily-trained neural network.” While much effort will be put into having as automated and clean a pipeline as possible, some human supervision is prudent.
Check out @deephypebot’s live timeline below for a “best of” collection of automatically generated music commentary!
Note: these retweets are best viewed on Twitter, where you can see the original tweets being replied to!
What I’ve Learned This Summer
UPDATE 10/7/18: “Advice on OpenAI Scholars” is a more comprehensive version of this section. Check it out!
I have a friend currently in a bioscience PhD program who likened my summer to a lab rotation (or two) during the first year of a PhD program. I essentially got a 13-week test run of what it might look like to join a great AI lab.
This summer has been an intense foray into the independence and self-determination required for graduate studies, and I couldn’t have done it without a solid support system! My biggest thanks goes to my program mentor, Natasha Jaques, who never failed to balance her own intensive research this summer with helping me out by proofreading my blog posts, explaining concepts on the whiteboard, providing me with access to other top experts in the field, brainstorming and debugging, and just generally encouraging and cheering me on. Thanks to program director Larissa Schiavo for keeping us together as a cohort and on track throughout the summer, always ready to unblock or assist us as needed. Thanks to my fellow Scholars for being truly brilliant and good-natured folks: Christine, Dolapo, Hannah, Holly, Ifu, Munashe, and Sophia. Last but not least, thanks to the family, friends, and coworkers both at Microsoft OneNote and the OpenAI offices for supporting me with places to work and stay across the country, as well as with room to grow on this summer “sabbatical.”
I am grateful for the time and space that this program provided me with to self-study at the intersection of deep learning and NLP. I learned about and experimented with n-gram language models, recurrent neural networks, conditioned LSTMs, seq2seq VAEs, the attention mechanism, various methods of interpreting model predictions, VAE latent space and selection bias, GANs, and LDA topic modeling. I dug deep into a single data set that I collected and gradually cleaned all summer, a particularly valuable exercise for me.
I found and refined my blogging voice, including more visual storytelling than ever before. I am much more comfortable working with deep learning frameworks, especially PyTorch and Keras. And I now have experience building an end-to-end, deep learning product in @deephypebot. Kudos all around!
Future Plans
- Moving back east!
- Going broader on/experimenting more with creative applications in ML - both new and existing.
- Even more explorations with NLP and language.
Thanks to everyone who has followed my journey as an OpenAI Scholar! You can find me on Twitter.
Follow my progress this summer with this blog’s #openai tag, or on GitHub.

Nadja does not particularly enjoy writing about herself.